
Multi-Instance AWE Core Integration Guide
About this Application Note
The Multi-Instance AWE Core Integration Guide is meant to guide users who wish to implement multiple instances of AWE Core and take advantage of the IPC audio routing and tuning communication features of AWE Core.
AWE Core Instance Overview
An instance of AWE Core can be thought of as the smallest individual addressable unit of AWE Core on an embedded target.
A single instance of AWE Core:
Has its own:
Unique Instance Id
Sampling rate and block size
Number of I/O channels
Set of AWE Core heaps (Fast, Fastb, Slow)
Module Table (ModuleList.h)
Number of processing threads
Is initialized once using awe_init()
Processes tuning packets addressed to its Instance Id
Performs audio processing on modules assigned to its Instance Id
When using Audio Weaver with an embedded target, it is mandatory to configure and initialize at least one AWE Core instance. In some applications and hardware configurations, creating two or more AWE Core instances on a target is desired.
Configuring multiple instances of AWE Core allows you to:
Distribute audio processing across multiple processing cores in a single design
Increase parallelism by assigning each AWE Core instance to a unique OS thread
Architect groups of features into their own instance to better monitor and analyze feature behavior
AWE Designer profiles CPU and memory usage per individual instance
Standard SoC Architecture Example
Consider a standard multicore SoC architecture:
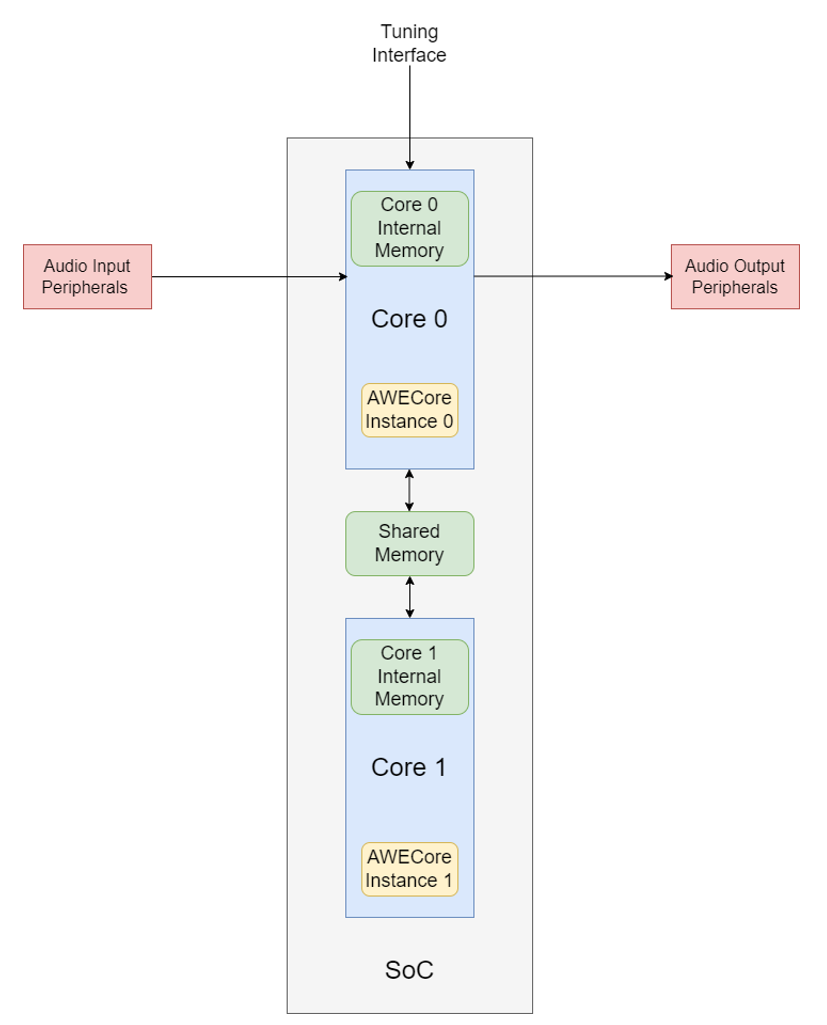
Figure 1. Generic Audio SoC Architecture
In this SoC architecture, there are two separate processing cores.
Core 0 has:
Access to the tuning interface
Access to all Audio I/O peripherals
Access to shared memory region
Its own internal memory region
Core 1 has:
Access to shared memory region
Its own internal memory region
In this typical multicore SoC architecture, an instance of AWE Core can be placed on each core. The shared memory of the SoC is utilized by AWE Core to communicate between the two instances, as well as buffer audio data between instances. AWE Core handles all data exchange between instances; no user protocol or software needs to be written to facilitate.
Setting Up Multi-Instance AWE Core
Initializing Shared Heap
To facilitate multi-instance with AWE Core, each AWE Core instance requires an initialization of the shared heap.
/*------------------MULTI-INSTANCE SUPPORT------------------*/
/** AWE Core shared memory definitions.
* OPTIONAL if using only single-instance AWE Core.
*/
/** The shared heap. */
volatile UINT32 *pSharedHeap;
/** The shared heap size. */
UINT32 sharedHeapSize;The shared heap is a contiguous section of memory which occupies the same physical address space for all AWE Core instances.
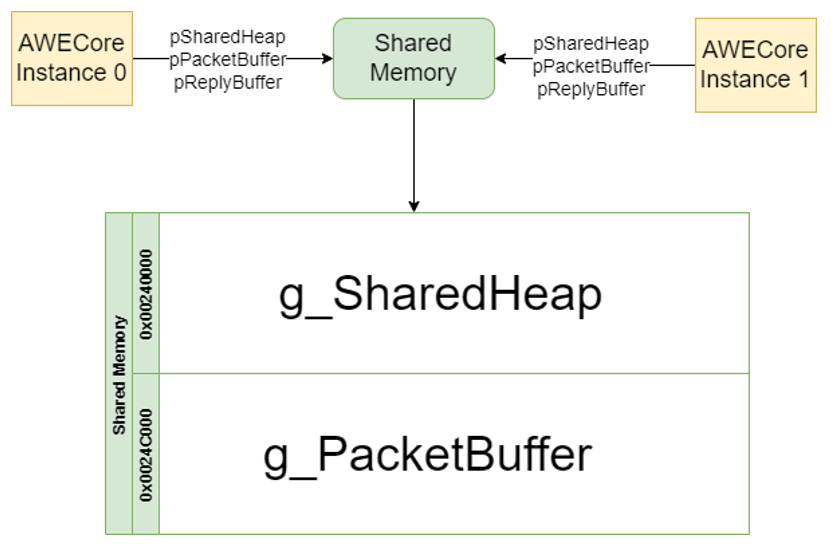
Figure 2. Shared Address Space Architecture
pSharedHeap points to this contiguous segment of memory. Every AWE Core instance in use is required to point to the same shared memory region address space. For this reason, shared heap must be placed in a shared memory region.
The size of this region is provided to AWE Core using sharedHeapSize.
Handling Multi-Instance Tuning Packets
Multi-instance AWE Core requires that the tuning packet buffer registered to each AWE Core instance occupy the same contiguous address space (see Figure 2).
Additionally, the pReplyBuffer reply buffer pointer registered to each AWE Core instance is required to point to the same packet buffer for multi-instance, as multi-instance AWE Core processes tuning packets in place.
/*------------------PACKET BUFFERS------------------*/
/* The Packet buffer pointer. */
UINT32 *pPacketBuffer;
/* Reply buffer pointer. */
UINT32 *pReplyBuffer;
/* Packet buffer size. */
UINT32 packetBufferSize;Each instance processes packets with the AWE Core API awe_packetProcessMulti().
/**
* @brief Multi-instance Wrapper for tuning packet processing.
* If called by the tuning instance, call whenever a complete packet is received. Wait until the return value is not E_MULTI_PACKET_WAITING to forward reply back to the tuning interface.
* If called by a non-tuning instance, poll continuously in a low-priority task.
* @param [in] pAWE The AWE instance pointer to process
* @param [in] isTuningInstance Boolean marking if the instance calling this API implements the tuning interface
* @return error @ref E_SUCCESS, @ref E_MULTI_PACKET_WAITING, @ref E_COMMAND_NOT_IMPLEMENTED, @ref E_MESSAGE_LENGTH_TOO_LONG,
* @ref E_CRC_ERROR, @ref E_BADPACKET
**/
INT32 awe_packetProcessMulti(AWEInstance * pAWE, BOOL isTuningInstance);Tuning Master Instance Usage
On the tuning master instance, this API is called whenever a complete packet has been received and is ready to be processed.
When this API returns E_MULTI_PACKET_WAITING, the packet has been forwarded to another instance to process. When this happens, this API should be repeatedly called by the tuning master instance until the return value changes. Only when a return value other than E_MULTI_PACKET_WAITING is received should the reply buffer be read and sent back to AWE Server.
See Core 0 Packet Processing for a usage example.
Non-Tuning Instance Usage
For non-tuning interface instances, this API is polled continuously. This is done so that the calling instance can check if it has been flagged by the tuning master instance and handle any packet processing if required.
For both tuning and non-tuning instances, the awe_packetProcessMulti() API must be called in a low-priority task, so as to not hold off audio processing.
See Core 1 Packet Processing for a usage example.
Assigning Unique Instance Ids
AWE Core’s instanceId parameter is used by AWE Designer to identify and address tuning packets to specific instances on an embedded target. For this reason, it is required that each AWE Core instance be registered with a unique instance Id.
The instanceId naming convention follows a linear increment starting at 0 (e.g. 0, 1, 2, etc..).
There are a few special behaviors assigned to the AWE instance with an instanceId of 0:
instanceId 0 must be the instance interacting with the embedded target’s tuning interface
instanceId 0 is the only instance that can use the System input/output pins of an Audio Weaver design. Consequently, it is the only instance which can use the awe_audioImportSamples() and awe_audioExportSamples()
The total number of AWE Core instances used in the application are provided to each instance with numProcessingInstances.
/* The ID of this instance. Single instance systems should always be 0. */
UINT32 instanceId;
/** The number of audio processing instances of AWE Core configured on a single target */
UINT32 numProcessingInstances;Processing Audio in Multi-Instance AWE Core
All AWE Core instances handle processing of audio in the same manner. Each instance has its own pump mask, retrieved with awe_audioGetPumpMask(), and uses the returned value to trigger the corresponding layout(s) to pump.
For multi-instance audio processing to function, each instance requires the same fundamental block size, as well as a unified global audio interrupt to synchronize all AWE Core instances.
It is required to trigger all instances on the target synchronously with the rate of audio buffer I/O. This is a user-specific piece of logic that could be a global RTOS event, global system software interrupt, or other similar logic. Most commonly, this means that a user must flag an interrupt in an audio DMA routine which all cores containing AWE Core instances react and trigger processing to.
Code Example for Standard SoC Architecture
Consider the generic SoC architecture from the Standard SoC Architecture Example.
Core 0 Initialization
Core 0 has a single AWE Core instance and allocates a shared heap memory segment before passing it to its AWE Core instance.
#define INSTANCE_ID (0)
#define AUDIO_BLOCK_SIZE (48)
#define SHARED_HEAP_SIZE (4*1024)
#define MAX_COMMAND_BUFFER_LEN (264)
__attribute__((__section__(".shared_heap")))
__ALIGN_BEGIN volatile UINT32 g_shared_heap[SHARED_HEAP_SIZE] __ALIGN_END;
__attribute__((__section__(".shared_packet")))
__ALIGN_BEGIN volatile UINT32 g_PacketBuffer[MAX_COMMAND_BUFFER_LEN] __ALIGN_END;
void AWEInstanceInit()
{
/** Other g_AWEInstance init code here **/
/* Set instanceId to 0 */
g_AWEInstance.instanceId = INSTANCE_ID;
/* Set fundamental block size (must be same for all instances) */
g_AWEInstance.fundamentalBlockSize = AUDIO_BLOCK_SIZE;
/* Set up packet buffer for multi-instance */
g_AWEInstance.packetBufferSize = MAX_COMMAND_BUFFER_LEN;
g_AWEInstance.pPacketBuffer = g_PacketBuffer;
g_AWEInstance.pReplyBuffer = g_PacketBuffer;
/* Define multi-instance setup */
g_AWEInstance.pSharedHeap = g_shared_heap;
g_AWEInstance.sharedHeapSize = SHARED_HEAP_SIZE;
g_AWEInstance.numProcessingInstances = 2;
awe_init(&g_AWEInstance);
}The memory section “.shared_heap” is defined to reside in the “shared memory” region of the SoC. Similarly, “.shared_packet” is defined to in the same shared memory region. This is to enforce the AWE Core requirement that all AWE Core instances must have access to the shared heap and packet buffer.
Core 1 Initialization
Similar logic is placed on Core 1, taking care that g_shared_heap and g_PacketBuffer are allocated in the exact same address space as on Core 0, and that this AWE Core instance receives a unique instanceId.
#define INSTANCE_ID (1)
#define AUDIO_BLOCK_SIZE (48)
#define SHARED_HEAP_SIZE (4*1024)
#define MAX_COMMAND_BUFFER_LEN (264)
__attribute__((__section__(".shared_heap")))
__ALIGN_BEGIN volatile UINT32 g_shared_heap[SHARED_HEAP_SIZE] __ALIGN_END;
__attribute__((__section__(".shared_packet")))
__ALIGN_BEGIN volatile UINT32 g_PacketBuffer[MAX_COMMAND_BUFFER_LEN] __ALIGN_END;
void AWEInstanceInit()
{
/** Other g_AWEInstance init code here **/
/* Set instanceId to 1 */
g_AWEInstance.instanceId = INSTANCE_ID;
/* Set fundamental block size (must be same for all instances) */
g_AWEInstance.fundamentalBlockSize = AUDIO_BLOCK_SIZE;
/* Set up packet buffer for multi-instance */
g_AWEInstance.packetBufferSize = MAX_COMMAND_BUFFER_LEN;
g_AWEInstance.pPacketBuffer = g_PacketBuffer;
g_AWEInstance.pReplyBuffer = g_PacketBuffer;
/* Define multi-instance setup */
g_AWEInstance.pSharedHeap = g_shared_heap;
g_AWEInstance.sharedHeapSize = SHARED_HEAP_SIZE;
g_AWEInstance.numProcessingInstances = 2;
awe_init(&g_AWEInstance);
}Core 0 Packet Processing
Finally, the multi-instance packet process API must be called in each core. Core 0 is the core containing the tuning interface, and triggers the packet process API only when a complete packet has been received.
void AWEIdleLoop(void)
{
while(TRUE)
{
/* g_bPacketReceived is a global flag set in tuning interface when
complete packet is received */
if (g_bPacketReceived)
{
/* Process the newly received packet */
/* Second argument is TRUE as Core 0 is tuning master */
if (awe_packetProcessMulti(&g_AWEInstance, TRUE) !=
E_MULTI_PACKET_WAITING)
{
/* Only reply if tuning instance isn’t waiting for a reply */
g_bPacketReceived = FALSE;
/* Send Reply back to PC */
User_ReplyFunction();
}
}
}
}Core 1 Packet Processing
Core 1 is not attached to the tuning interface, and only needs to repeatedly poll the packet process API.
void AWEIdleLoop(void)
{
while(TRUE)
{
/* Check for and process packet if it exists */
/* Second argument is FALSE as Core 1 is not tuning master */
awe_packetProcessMulti(&g_AWEInstance, FALSE);
}
}Core 0 Audio Processing Synchronization
Instance 0 is the only instance which interfaces with AWE Designer’s I/O pins, and is also the instance which needs to synchronize the audio processing of every other instance.
Below is a generic code snippet of what an audio processing routine on instance 0 would look like.
/* This is a callback tied to the audio processing clock domain */
void AudioDMACallback(void)
{
/* Insert the received CODEC samples into the Audio Weaver buffer */
awe_audioImportSamples(&g_AWEInstance, &CODECBufferIn[0], STRIDE2, CHANNEL1, Sample16bit);
awe_audioImportSamples(&g_AWEInstance, &CODECBufferIn[1], STRIDE2, CHANNEL2, Sample16bit);
/* Insert the processed Audio Weaver samples into the USB buffer */
awe_audioExportSamples(&g_AWEInstance, &USBBufferIn[0], STRIDE2, CHANNEL1, Sample16bit);
awe_audioExportSamples(&g_AWEInstance, &USBBufferIn[1], STRIDE2, CHANNEL2, Sample16bit);
/* Get layout mask and pump audio accordingly */
INT32 layoutMask = awe_audioGetPumpMask(&g_AWEInstance);
// If higher priority level processing ready pend an interrupt for it
if (layoutMask & 1)
{
/* Pump layout 0 */
/* One can also trigger this logic from here to take place in a
different interrupt context */
awe_audioPump(&g_AWEInstance, 0);
}
if (layoutMask & 2)
{
/* Pump layout 1 */
awe_audioPump(&g_AWEInstance, 1);
}
/* Trigger global interrupt within synchronous callback */
/* (the following is a silicon-specific API, many others like it can be used
to signal to each core to pump) */
MU_TriggerInterrupts(MUA, kMU_GenInt0InterruptTrigger);
}Core 1 Audio Processing Synchronization
Core 1 does not have any physical audio I/O connected to it. Core 1 also needs to react to Core 0’s global interrupt flag to process its own audio. No import or export API is called, because only instance 0 can interface with AWE Designer’s I/O pins.
/* This callback is registered to the generic global interrupt flagged by Core 0
This will handle all audio processing for Core 1.
It is NOT tied to any audio peripheral or DMA event */
void GenInt0Callback(void)
{
/* Check the pump mask and pump audio accordingly */
INT32 layoutMask = awe_audioGetPumpMask(&g_AWEInstance);
/* If higher priority level processing ready pend an interrupt for it */
if (layoutMask & 1)
{
/* Pump layout 0 */
/* One can also trigger this logic from here to take place in a
different interrupt context */
awe_audioPump(&g_AWEInstance, 0);
}
if (layoutMask & 2)
{
/* Pump layout 1 */
awe_audioPump(&g_AWEInstance, 1);
}
}Creating multi-instance designs in Audio Weaver
Audio Weaver provides a single design canvas which can place modules on any instance. Audio data can be routed between instances in one design file, which allows users to move processing loads seamlessly to available cores on an embedded target. The below example canvas has processing distributed over two AWE Core instances residing on two different processing cores.
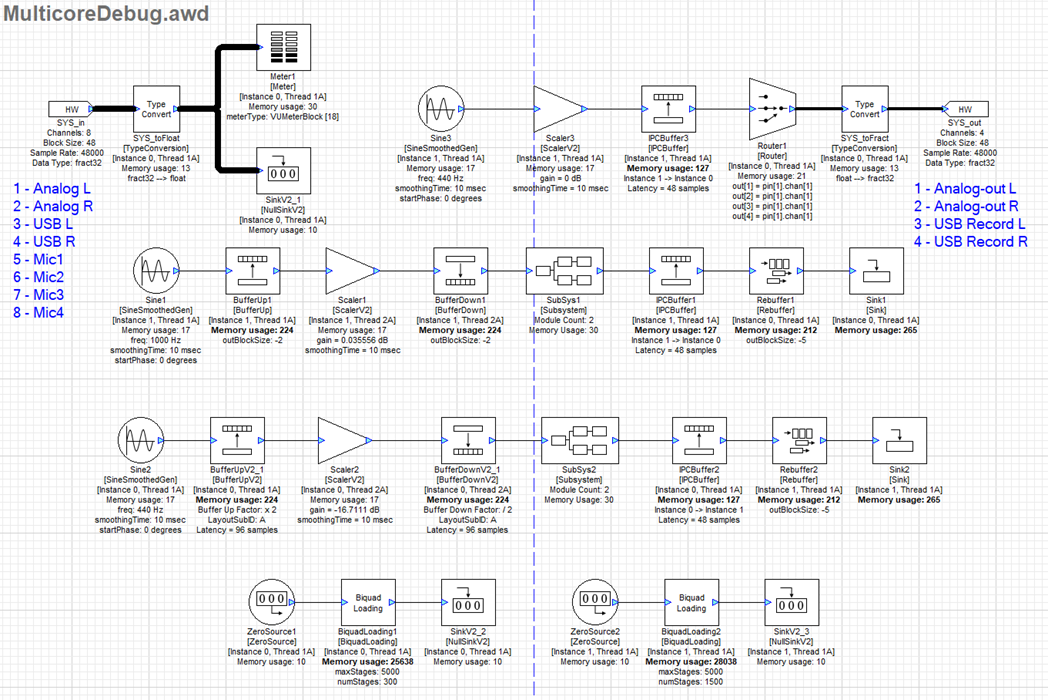
Figure 3. Multi-instance Canvas
When connected to a multi-instance target, AWE Designer will show a module’s current instance ID below the module:
Figure 4. Module Instance Identification
The instance ID of a module is propagatable between modules, which means that if the output of a module on instance ID 0 is routed to another module, that second module will inherit the instance ID and process on instance ID 0 as well.
There are two ways of changing the instance ID of a module.
Using the IPCBuffer module
(Source modules only) Modify the clockDivider field of a module
IPCBuffer Module
The IPCBuffer module is a simple module which takes an input data wire, and using a tunable parameter targetInstance, directs this data to a new instance. Modules connected to the output of the IPCBuffer module will inherit this new instance ID.
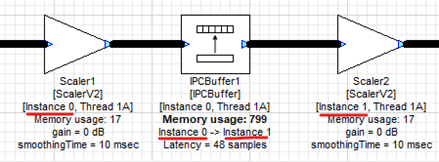
Figure 5. IPCBuffer Example
Changing the instance ID of a Source module
For source modules (modules which do not have an input wire), one can change the instance ID by modifying the clockDivider field of the module.
Take as an example a sine generator module:
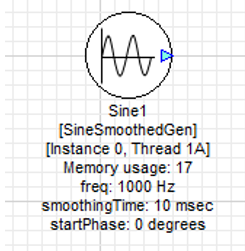
Figure 6. Initial Sine Generator State
When dragged into the canvas, the module always defaults to ‘Instance 0’.
To reach the clockDivider field, right-click on the module and select View Properties.
In the bottom pane that appears, select the Build tab, and locate the clockDivider field.
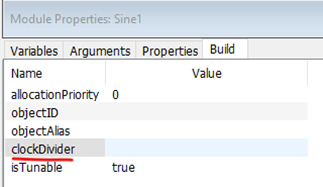
Figure 7. clockDivider field
The encoding for the clockDivider field is Thread ID + Instance ID.
As an example, let’s keep the thread ID in its default thread of ‘1A’. However, it is desired in this example to change the instance ID to 1. Thus, the clockDivider field should be set to ‘1A1’.
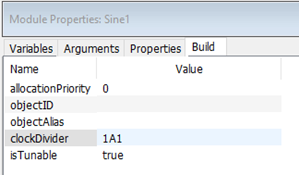
Figure 8. Modified clockDivider
Finally, click the Propagate Changes button at the top of Designer to register the change with the module. The resulting module text will update to report the change in Instance ID.
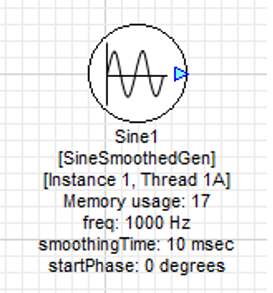
Figure 9. Sine Generator in Instance 1
Loading Multi-Instance Designs in AWE Core
Multi-instance designs created in Designer are exported as a single binary file (in .awb or C array format) which encompasses all AWE instances.
Multi-instance designs are required to be loaded from the tuning master instance. If the AWE Core flash file system is used for storing and loading a multi-instance design, the flash file system is required to be attached to the tuning master instance. Similarly, when loading a multi-instance design by a static C array, the C array must be read by the tuning master instance.
At the time a multi-instance design is loaded, all AWE instances must be initialized. Failure to ensure this sequencing can result in the multi-instance design load to infinitely pend on a response from an uninitialized instance.
//Example Setup Code, g_AWEInstance is tuning master instance
awe_init(&g_AWEInstance);
//At this point in the code, all AWE instances should be initialized and reachable
//Load multi-instance design from the tuning master instance (g_AWEInstance)
UINT32 position;
INT32 ret = awe_loadAWBfromArray(&g_AWEInstance, Core0_InitCommands, Core0_InitCommands_Len, &position);Loading multi-instance designs on a single-core target
A single-core architecture can support multi-instance AWE Core, where both a tuning master instance and non-tuning instance(s) exist on the same core. In this architecture, one additional integration step is required when loading a multi-instance design.
AWE Core needs to access all instances on the core to load a multi-instance design. The API awe_setInstancesInfo() is used to register these instances with AWE Core. This API needs to be called before any multi-instance design is loaded.
See the following usage example:
// There are two AWE instances on this core
#define NUM_INSTANCES_ON_CORE (2)
// Table of AWE Instances used for single-core multi-instance applications
AWEInstance *pInstances[NUM_INSTANCES_ON_CORE];
// Initialize AWE signal processing instance
awe_init(&g_AWEInstance1);
awe_init(&g_AWEInstance2);
// Initialize Instance Table with AWE Core
pInstances[0] = &g_AWEInstance1;
pInstances[1] = &g_AWEInstance2;
awe_setInstancesInfo(pInstances, NUM_INSTANCES_ON_CORE);
// Load multi-instance design
UINT32 position;
INT32 ret = awe_loadAWBfromArray(&g_AWEInstance1, Core0_InitCommands, Core0_InitCommands_Len, &position);Summary
Utilizing multi-instance AWE Core requires these steps:
Allocate a shared heap memory space in a memory region accessible to all AWE Core instances.
Allocate the tuning packet buffer in a shared memory region accessible to all AWE Core instances. Initialize the reply buffer pointer to the same memory region as the packet buffer.
For each AWE Core instance, provide the shared heap and shared packet buffer, ensuring they occupy the same address space in memory for each instance.
Provide a unique instanceId to each AWE Core instance, with instanceId 0 reserved for the AWE Core instance connected to the tuning interface.
Set the numProcessingInstances member of each AWE Core instance to the total number of AWE Core instances on the target system.
Using a global software interrupt accessible to all AWE Core instances, trigger each instance to check their pump mask and pump. This trigger is required to be synchronous to the audio peripheral data passed in/out of AWE Core instance 0.
Process packet buffer data using the multi-instance packet process API. For the tuning master instance, the API is called once a complete packet is received. For non-tuning instances, the API is polled in a low-priority task.