
Wake Word Engine and ASR Integration for AWECore
This application note describes how Wake Work Engine and ASR commands work with Audio Weaver. The first section of this document contains information about VR (Voice Recognition) State, why we’d need it and details of its implementation. The second section contains information about the implementation of the VR State in the TalkToSample App.
VR State
What is a VR State?
The VR( Voice Recognition) State is information from the cloud to the AWECore instance and tells it to listen to the ASR commands. As soon as the cloud notifies the AWECore instance, the value of the VR State changes to 0/1.
Why do we need a VR State?
VR State is needed to make sure that important speech content is not cancelled in the interference cancellation algorithm.
As soon as the cloud notifies the AWECore instance to listen to the ASR commands, the Interference Cancellation and DOA( Direction of Arrival) algorithms stop adapting to incoming speech and store the latest filter coefficients. This is especially important in the case where the noise levels and speech levels are almost the same. In that case, the DOA algorithm could point to the speech direction as noise, thereby eliminating the speech in the Interference Cancellation.
Implementation of the VRState
Figure 1 below shows the implementation of the VR State. As can be seen in the figure, the VR State becomes active as soon as the Trigger Word is detected. When either of the Wake Word Engines are triggered, the application code should set the VR State to 1 and ignore the other WWE to eliminate double triggers.
Once the VR State becomes active, it listens to the ASR commands. In cloud-based systems, the information on the end of utterance is provided. As soon as the end of utterance information is provided to the AWECore instance, the VR State becomes inactive.
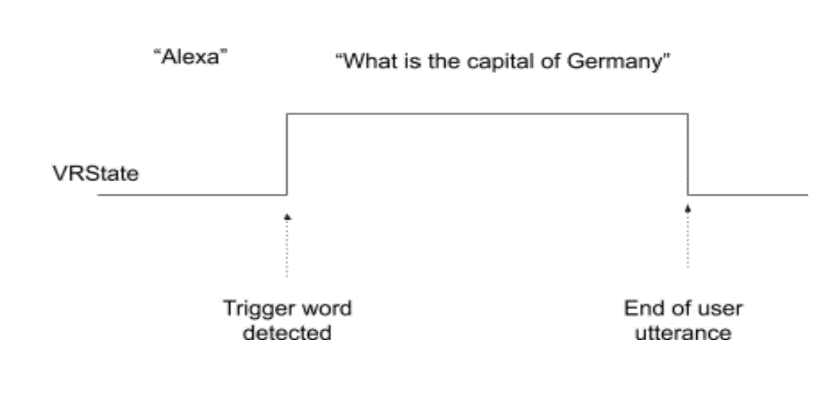
In the TalkTo Sample App, the VR State becomes 0 once a timeout is reached. However, the most efficient way to implement the VR State is through notification of end of utterance, which is the case in cloud-based systems.
Implementation of the VR State in TalkTo Sample App:
Basic Introduction of TTSA
Initialization of AWECore Instances
In the TalkTo Sample App, two instances of Audio Weaver processor are instantiated- VUI processor and Playback Processor. The VUI processor processes the incoming microphone data before feeding it to the Sensory™ Phrase Spotters.
The Playback Processor is loaded with the songs that are sent to the audio output.
For more information, check the README file in TalkTo Sample App.
WWE and ASR
Three Sensory phrase spotters are instantiated.
Two of them are loaded with a wake word model that responds to the phrase
AlexaThe third spotter is loaded with an ASR model that responds to the following phrases:
play music,stop music,pause music,next song,previous song
Sensory phrase spotter instances are created by the constructor of the TalkToSampleApp class.
The code below creates the first instance of Sensory:
trigger0Spotter = std::make_unique<SensoryPhraseSpotter>(config.trigger0SpotterModelFilename,
config.trigger0SpotterSensitivity,
trigger0SpotterCallbackFunction,
this);The following code creates the second instance of the Sensory:
trigger1Spotter = std::make_unique<SensoryPhraseSpotter>(config.trigger1SpotterModelFilename,
config.trigger1SpotterSensitivity,
trigger1SpotterCallbackFunction,
this);The third one is created by the code below:
commandSpotter = std::make_unique<SensoryPhraseSpotter>(config.commandSpotterModelFilename,
config.commandSpotterSensitivity,
commandCallbackFunction,
this);Audio Data:
The
PumpAudiofunction shown below takes the incoming microphone audio data in the input buffer, processes it and the output buffer is fed to the WWE and Command Spotter Engines.
error = vuiProcessor->PumpAudio(vuiInputBuffer, vuiOutputBuffer,
config.numVuiInputChannels * framesPerBuffer,
config.numVuiOutputChannels * framesPerBuffer);The code below shows how we feed the audio data to the Sensory engine. The three buffers-
trigger0SpotterBuffer,trigger1SpotterBufferandcommandSpotterBufferare fed with the outputs of thePumpAudiofunction and the sensory engines process these buffers to spot ASR commands or Wake Words .
error = trigger0Spotter->process(trigger0SpotterBuffer, (int) framesPerBuffer / config.decimationRatio);
throw_assert(error == 0, "trigger0Spotter->process() -> " << error);
error = trigger1Spotter->process(trigger1SpotterBuffer, (int) framesPerBuffer / config.decimationRatio);
throw_assert(error == 0, "trigger1Spotter->process()");
error = commandSpotter->process(commandSpotterBuffer, (int) framesPerBuffer / config.decimationRatio);
throw_assert(error == 0, "commandSpotter->process()");Implementation of the VR State
Trigger Spotter Callback functions and implementation of Voice Recognition State (VRState):
As shown in the code below, one of the callback functions(
trigger0SpotterCallbackortrigger1SpotterCallback) is triggered when a keyword is detected.
int TalkToSampleApp::trigger0SpotterCallback(const std::string &phrase, double begin, double end) {
// This function sets the timeout to config.vrStateTimeout
vrStateGenerator->signalWakeWordDetection();
return 0;
}
int TalkToSampleApp::trigger1SpotterCallback(const std::string &phrase, double begin, double end){
vrStateGenerator->signalWakeWordDetection();
return 0;
}A timer is used to prevent double triggering of the wake word.
As soon as the wake word is detected, a timeout value is set , the VR State becomes active, and the Playback Processor ducks playback. The VR State remains active until a timeout value is reached or an ASR command is detected.

In the TalkToSampleApp, the timeout value is set for 180 blocks. At a block size of 768 and sampling rate of 48000Hz, this corresponds to a timeout value of 2.88 seconds.
If no ASR command is detected for 2.88 seconds after the detection of the wake word, the VR state becomes inactive.
Command Spotter Callback functions and implementation of VR State:
The Command Spotter Callback function shown below is triggered when an ASR command is spotted.
int TalkToSampleApp::commandSpotterCallback(const std::string &phrase, double begin, double end) {
……
vrStateGenerator->signalCommandDetection();
if (songProvider->isSongPlaying()) {
std::cout << "Playing song " << songProvider->getCurrentSong() << "\n";
}
else {
std::cout << "Playback stopped" << "\n";
}
return 0;
}As soon as the ASR command is detected, the timeout value is set to 0, thereby making the VRState inactive.

Audio Callback and VR States:
The function
audioCallbackshown below reads the current VR State and compares it with the previous VR State.If there is a change in the VR State, the updated VR State is then displayed on the screen.
When the VR State changes, the AWECore instance of the VUI processor is notified.
AudioStream::CallbackResult
TalkToSampleApp::audioCallback(const void *hardwareCaptureBuffer, void *hardwarePlaybackBuffer,
unsigned long framesPerBuffer, AudioStream::CallbackFlag statusFlag) {
unsigned int vrStatePrevious = vrState;
vrState = vrStateGenerator->getState();
//check the status
if (vrStatePrevious != vrState) {
cout << "Setting AWE_VRState to " << vrState << "\n";
AWE_VRState[0].iVal = vrState; //Set VRState
error = vuiProcessor->SetValues(MAKE_ADDRESS(AWE_VRState_ID, AWE_VRState_value_OFFSET), AWE_VRState_value_SIZE
AWE_VRState);
throw_assert(error == 0, "vuiProcessor->SetValues(AWE_VRState) returned " << error);
cout << "Setting AWE_duckPlayback to " << vrState << "\n";
AWE_duckPlayback[0].iVal = vrState; //Set VRState
error = playbackProcessor->SetValues(MAKE_ADDRESS(AWE_duckPlayback_ID, AWE_duckPlayback_value_OFFSET),
AWE_duckPlayback_value_SIZE, AWE_duckPlayback);
throw_assert(error == 0, "playbackProcessor->SetValues(duckPlayback) returned " << error);